data structure
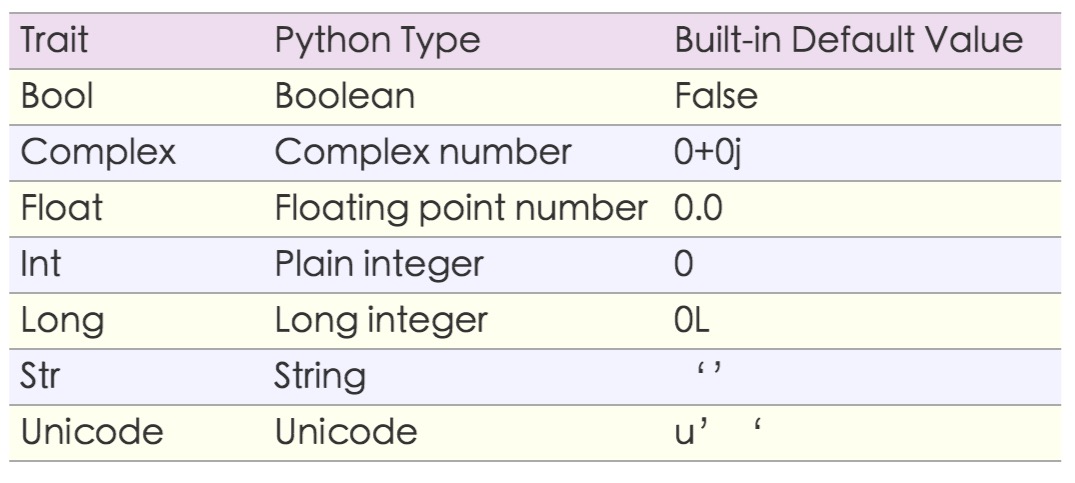
数据类型
- None immutable 不是保留关键字,NoneType的一个实例
- str
'a' "a"immutable - tuple元组
(3,4)immutable的对象序列 - unicode immutable
- int float long immutable
- bool immutable
- list
- set unique
- dict key-value
- np数组
True False
\转义
数字进制
print(0b1110) # 二进制,以0b开头
print(0o10) # 八进制,以0o开头
print(0x2A) # 十六进制,以0x开头
数组
数组index
范围引用: 基本样式[下限:上限:步长]
尾部元素引用(tuple and list)
数组range & xrange
xrange不会预先产生所有的值,并将它们保存到列表,而是返回一个逐个产生整数的迭代器
内置的序列函数
enumerate 返回(index, item)
enumerate(collection)
- sorted 返回有序的list 接受iterable对象参数
- reversed 按逆序迭代元素
list(reversed(range(10)))
zip(seq1, seq2, ...) 返回tuple的list,舍弃冗余 zip(*some_tuple_list)
如果你多个等长的序列,然后想要每次循环时从各个序列分别取出一个元素,可以利用zip()方便地实现:
ta = [1,2,3] tb = [9,8,7] tc = ['a','b','c'] for (a,b,c) in zip(ta,tb,tc): print(a,b,c)
for i, (a, b) in enumerate(zip(seq1, seq2)):
print('%d: %s, %s' % (i, a, b))
string
as list
raw_input("input u idiot :")
print "%.2f" % (total)
character in string
c = "cats"[0]
method
len(string) and str(object), but dot notation (such as "String".upper()) for the rest
- len(str)
- .lower()
- .upper()
- str(str)
- .isalpha()
print "Hello %s" % (name)
print "The %s who %s %s!" % ("Knights", "say", "Ni")
numberOfLines = len(fr.readlines())
for line in fr.readlines():
line = line.strip() # 去掉文本回车
listFromLine = line.split('\t')
tuple ()
tuple元素不可变,list元素可变
tuple有隐含or的意思,可以作为dict的key
(3,'q') + (0) #(3, 'q', 0)
tup = 4, 5, (7, 9)
a, b, (c ,d) = tup #d = 9`
tup.cpunt(2) #2出现的次数
list []
l = [item1, item2]
逆向负数索引
- len(l)
- l.count(some_value)
- l.append(item) l.remove(item)
- l.insert(index, item) l.pop(index)
- l.index(item1) # in set;use for item in list
- l.sort()
- print "--".join(l) #分隔符
- "+"
[None, 4] + [2, (2, 'a')] #[None, 4, 2, (2, 'a')] - l.extend(some_list) 合并list
- l.sort .sort(key=len) 就地排序(按长度)
- l.is_unique
[0]*3 # 初始化[0, 0, 0] 区别np.zeros((3)) [0. 0. 0.]
del(l[index])
- mean(l)
`for itemt in range(0, len(l))
l.append(["O"] * 5)`
dict {}
与表不同的是,词典的元素没有顺序。你不能通过下标引用元素。词典是通过键来引用
- dic.get(index, def_value)
- dic.keys()
- dic.values()
- dic.items() 返回dic所有的元素(键值对)
- dic.clear()
- del dic['tom']
- dic.iteritems() #dict的value的iter对象,可用于sorted/reversed
本质上是二元组集
dict(zip(list_a, list_b))
d = {'key1' : 1, 'key2' : 2, ('key3', 'key4') : 7}
print d['key1']
del d[key]
d.pop('key3', defvalue)
d.get('key3', defvalue)
d.items()
d.keys() #key list
d.values() #value list,**not iterable**
4 in d #False
d.update(some_dict) #合并dict
d.setdefault(key, defval).append(val) #有key append, 无key设置位defval
import collections import defaultdict
defaulydict(list) #默认defval 为[]
两个相同key的dict可以一起循环
默认只循环key
for key in d
print d[key]
双项循环
for index, item in enumerate(d):
zip 合并,舍弃冗余项
for a, b in zip(list_a, list_b): #[(a1, b1), (a2, b2) ]
set(集合) set([]) 和 {}
set([1, 2, 2]) #set([1, 2])
集合运算结果是set ;& | - ^ set_a.issubset(set_b) .superset
set有两种 set frozenset(元素不可变,不支持add remove操作)
- seta.intersection(setb) # seta.intersection(item)也行
sort
operator.itemgetter 返回 获取对象的哪些维的数据 的函数对象
import operator
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
sorted(students, key=lambda student : student[2], reverse=True)
sorted(students, key=operator.itemgetter(2)) # equal
# key=operator.itemgetter(0,2) 对第0个/第2个域排序 ;
# dict 两个域 sorted(dict) 返回格式[(key, value)...]
二分查找
bisect不会判断原序列有序
import bisect
bisect.bisect(some_list.3) #找出插入位置
bisect.insort(some_list.3) #插入位置
动态类型
即使是多个引用指向同一个对象,如果一个引用值发生变化,那么实际上是让这个引用指向一个新的引用,并不影响其他的引用的指向
- 改变对象自身(in-place change) #做函数参数改变原值
- 不可变数据对象(immutable object) #做函数参数不改变原值(可读),可以用global(局部作用域用nonlocal) 声明成in-place var
- int str
- tumple
推导式
在一组序列对象上执行相同的操作,返回序列对象
[expr for val in collection if condition]
{key-expr : value-expr for key, value in enumerate(collection) if condition}
{expr for val in collection if condition}
dict((key-expr, val-expr) for key, val in enumerate(sone_list))
{key-expr : val-expr for key, val in enumerate(sone_list)}
[json.loads(line) for line in open(path)]
for 嵌套
name-expr for names in family for name in names ...
语法
Exception异常
如果无法将异常交给合适的对象,异常将继续向上层抛出,直到被捕捉或者造成主程序报错
- try: ... except exception: ... else: ... finally: ...
- raise exception
try: for i in range(100): print re.next() except StopIteration: print 'here is end ',i except: print("Not Type Error & Error noted")
try: assert 1 == 2,'1 is not equal 2' except Exception,e: print '%s:%s' %(e.class.name,e) pass
type convertion类型转换
convertion
int("33")
list(var)
bool(var)
set(var)
hash(var) #hash函数,本质上不是理解的类型转换
判断
type(a)
type(obj).__name__=='dict'
isinstance(a, (int, float))
isinstance(3,(int,float))
None不是保留关键字,而是NoneType的一个实例
二元运算符
is 判断引用相等
== value相等
**次方
& | 逻辑判断or对于整数按位与或
^ 异或
loop
- range()
- enumerate() #for (index, value) in enumerate(struct)
- zip()多个等长的列 # for (a,b,c) in zip(ta,tb,tc):
生成器 yield
定义了 __iter__ next()的对象
class count_iterator(object):
def __iter__(self):
return self
def next(self):
pass
a_l.extend(b_l) 是一个迭代器方法
但是在你的代码中的是一个生成器,这是不错的,因为:
你不必读两次所有的值
你可以有很多子对象,但不必叫他们都存储在内存里面。
并且这很奏效,因为Python不关心一个方法的参数是不是个链表。Python只希望它是个可以迭代的,所以这个参数可以是链表,元组,字符串,生成器... 这叫做 duck typing,这也是为何Python如此棒的原因之一
生成器是可以迭代的,但是你 只可以读取它一次 ,因为它并不把所有的值放在内存中,它是实时地生成数据
mygenerator = (x*x for x in range(3))
for i in mygenerator :
...
def createGenerator() :
... mylist = range(3)
... for i in mylist :
... yield i*i
yield 是一个类似 return 的关键字,只是这个函数返回的是个生成器
调用这个函数的时候,函数内部的代码并不立马执行 ,这个函数只是返回一个生成器对象
迭代是一个实现可迭代对象(实现的是 iter() 方法)和迭代器(实现的是 next() 方法)的过程。
itertools包含了很多特殊的迭代方法
I/O file读写
- Read-only: r
- Write-only: w
- Append a file: a
- Read and Write: r+
- Binary mode: b
- Note: Use for binary files, especially on Windows.
open()返回的实际上是一个循环对象,包含有next()方法。而该next()方法每次返回的就是新的一行的内容,到达文件结尾时举出StopIteration
content = f.read(N) # 读取N bytes的数据
content = f.readline() # 读取一行
content = f.readlines() # 读取所有行,储存在列表中,每个元素是一行。
f.write('I like apple') # 将'I like apple'写入文件
关闭文件:
f.close()
with open('x.txt','r') as f:
data = f.read()
conditional 条件关系
and or not
== !=
if exp:
elif exp:
else:
while exp:
else
for value in collection/interator:
else: #executed only if for ends normal(e.g. break makes else no-running)
pass
break
continue
嵌套
def a:
def b:#b只在a执行时定义,a运行结束后销毁
class
metaclass
“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。” —— Python界的领袖 Tim Peters
元类的主要用途是创建API
class A声明A是一种类/metaclass(元类)对象,A.metaclass是元类,元类就是用来创建类的“东西”(类的工厂类)。使用class关键字时,Python解释器自动创建这个class对象.
class A(object):
pass
理解为
A = MetaClass(); obj = A()
背后由type实现。这是因为函数type实际上是一个元类。type就是Python在背后用来创建所有类的元类。type就是创建类对象的类
def foo:
pass
print foo.__class__ # <type 'function'>
print foo.__class__.__class__ # <type 'type'>
type可以接受一个类的描述作为参数,然后返回一个元类对象
type(类名, 父类的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
class FooChild(Foo):
def echo_bar(self):
print self.bar
pass
等价于
# type组装
def echo_bar(self):
print self.bar
FooChild = type('FooChild', (Foo,), {'echo_bar': echo_bar}) # 返回一个类对象
自定义metaclass
# 请记住,'type'实际上是一个类,就像'str'和'int'一样
# 所以,你可以从type继承
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# 你很少用到__new__,除非你希望能够控制对象的创建
# 这里,创建的对象是类,我们希望能够自定义它,所以我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 还有一些高级的用法会涉及到改写__call__特殊方法,但是我们这里不用
def __new__(upperattr_metaclass, future_class_name, future_class_parents, future_class_attr):
attrs = ((name, value) for name, value in future_class_attr.items() if not name.startswith('__'))
uppercase_attr = dict((name.upper(), value) for name, value in attrs)
return type(future_class_name, future_class_parents, uppercase_attr)
装饰器
- @property
- @staticmethod
- @classmethod
def __init__(self, var):
pass
def func(self):
pass
# @classmethod因为持有cls参数,可以来调用类的属性,类的方法
@classmethod
def method(cls,...)
print cls.class_var
公共属性
__class__
__metaclass__ 在类的定义时,Python就会用它来创建类,如果没有找到,就会用内建的type来创建这个类
hasattr(Foo, 'bar')
example
所有python对象共有三个属性:id,type,value
class Student(object):
wtf = 'ttt' # class var
def __init__(self, name, item):
self.name = name # obj var
self. __set_item()
self.some_list = [] # init others; optional
def set_age(self, age):
self.age = age
def __set_item(self, item): # private method
self.__item = item # private value
update_item = __set_item # copy private method
c = Student('jack')
print c.wtf, Student.wtf, c.name, c.age
print c.update_item('some_item')
Multiple Inheritance: class DerivedClassName(Base1, Base2, Base3):
- child不可访问parent的private 成员
- 没有重载(不同参数匹配函数)概念,因为每个函数都是一个class对象
- super(Child, self);父类引用
class MaleStudent(Student):
def update_item(self, item):
super(MaleStudent, self).update_item(self, item)
self. data = data
function
函数是特殊的class
- 每个def都是一个带call(args...)的class定义
- function无继承结构,所以加载文件不会执行作用域的代码
var_lam = lambda x,y: some_expression(x,y)
没有显式return,隐式返回None
type(arg)
def func(a, b=2) return
a 入元组args;bkwargs入kwargs
可以返回tuple(多个值)
function args & unpacking (*args, **kwargs)
- 按需 按序 读必需/非必需参数
- 包裹传递
- def func(*name): name as tumple
- def func(**dict): dict前加**
* ** vs zip
* (tuple/list)unpacking to tuple
** dict unpacking to tuple
zip list/tuple packing to [tuple]
summary
先位置,再关键字,再包裹位置,再包裹关键字,并且根据上面所说的原理细细分辨。
包裹和解包裹并不是相反操作,是两个相对独立的过程。
lambda 匿名函数对象(as data)
var = lambda x: x-expr
reduce(lambda a, b: a * b, xrange(1, 5))
操作函数对象的函数
Python 3.X中,map(),filter(),reduce()的返回值是一个循环对象。可以利用list()函数,将该循环对象转换成表
map
re = map((lambda x,y: x+y),[1,2,3],[6,7,9])
filter
如果函数对象返回的是True,则该次的元素被储存于返回的表中
reduce
reduce()函数在3.0里面不能直接用的,它被定义在了functools包里面,需要引入包
reduce函数的第一个参数也是函数,但有一个要求,就是这个函数自身能接收两个参数。reduce可以累进地将函数作用于各个参数
reduce((lambda x,y: x+y),[1,2,5,7,9]) 相当于(((1+2)+5)+7)+9
skill
- if name == 'main': pass` prevent code running on module loading
- def variable_args(args, *kwargs):
- object_name.
# all attributions - funcname? modulename?
- who whos
写法
if condition: some_code
somecode ; some_other_code
code \
code
add sys path
import sys
sys.path.append("../../base/")
import Network #自定义import 空两行
add 自定义的path
import sys
new_path = '/home/emma/user_defined_modules'
if new_path not in sys.path:
sys.path.append(new_path)
内存对象判断
id(a) == id(b)
path
- 程序所在的文件夹
- 标准库的安装路径
- 操作系统环境变量PYTHONPATH所包含的路径
sys.path # 查看当前的search path;;export PYTHONPATH=$PYTHONPATH:/.../
package
A directory that contains many modules
A special file called init.py (which may be empty) tells Python that the directory is a Python package, from which modules can be imported
查询
- dir() module.file#查询一个类或者对象所有属性
- hasattr(obj, attr_name) # attr_name是一个字符串
- getattr(obj, attr_name)
- help() some? #查询说明文档
使用obj.class.name来查询对象所属的类/名称;.base查询某个类的父类;module.file 看module文件位置
查询函数的参数 `import inspect print(inspect.getargspec(func))
@ipython>>> %psearch np.diag* 寻找函数 or help xxx
@numpy>>> numpy.lookfor('convolution') or numpy.lookfor('remove', module='os')
脚本与命令行context结合
可以使用下面方法运行一个Python脚本,在脚本运行结束后,直接进入Python命令行。这样做的好处是脚本的对象不会被清空,可以通过命令行直接调用。
$python -i script.py